결과가 이상하다면 예민하게 원인을 분석하자
오늘은 굉장히 자존심이 상했던 학부연구생 프로그램의 final project에 대해서 리뷰하고자 한다.
이 프로젝트는 한 학기동안 음성인식에 대한 공부를 함께 하고 학부생 수준에 맞게 연구실 선배가 만든 프로젝트로,
colab을 사용해 구현한 python 음성인식 코드에 한 오류를 고치는 과제였다.
나는 나름 석사생인데 학부생의 프로젝트를 완벽하게 하고 싶었던 나는 조금 긴장했었지만,
코드를 훑어보니 이상한 부분을 쉽게 찾아낼 수 있었다.
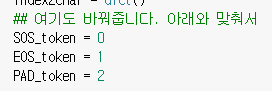
token설정 부분이었다. 간단하다고 생각하며 바로 수정해주었다.


하지면 부끄럽게도 정답은 그게 아니였다.
먼저 저 부분이 정답이 아닌 이유는 아래와 같다.
dataset and model Initialization 하는 단계를 보면 아래와 같은 코드가 있다.
해당 코드는 각 특수 토큰에 대해 바로 index로 불러오는 코드다.
그러니까 특별히 token 번호를 따로 설정해주지 않아도 된다는 것이다.
~~token = 0이라고 되어 있던 부분은 틀린 것이 아니라 없어도 되는 코드였다.
SOS_token = char2index['<sos>']
EOS_token = char2index['<eos>']
PAD_token = char2index[' ']한편 진짜 정답은 음성 data의 sampling rate가 다르다는 것이다.
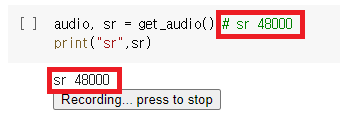
아래를 보면 pretrain된 모델의 sampling rate와 추가 데이터의 sampling rate가 16k와 48k로 다른 것을 확인할 수 있다.

대놓고 써있다. 이 정도면 떠먹여 주려고 한 것 같은데...
왜 몰랐을까?
sampling rate를 맞추는 건 기본이고 또 음성인식 결과가 그렇게 안좋으면 당연히 의심했어야 하는데…
아무튼 나는 틀린 답에 대한 부연 설명도 했다.
ㅋㅋㅋㅋ부끄럽다…

그 외에도 과제를 잘 하고 싶어서 깔끔한 코드를 위해 노력했다…
사용하지 않는 코드에서 error가 떠서 지우고
<unk>를 없애기 위해 return마다 replace사용해서 출력을 예쁘게 만들었다. 이 때는 token자체를 건드리면 차원이 변하므로 replace 함수를 사용했다.
그 외에도 finetuning 중 best model을 사용하는 코드를 작성하며 석사생으로서의 면모를 보이고자 애썼다.

하지만 나의 노력에도 애초에 결과 자체가 좋지 않았다.
(당연함. sampling rate가 안맞음.)

위 그림의 빨간 네모와 같이 전혀 쌩뚱맞은 결과가 나왔다.
여기서 내가 의문을 품어야 했던 부분은 두 가지다.
첫째 왜 저렇게 결과가 거지같이 나오는가?
둘째 왜 서로 다른 세 문장의 추론에 대해 같은 결과가 나오는가?
하지만 나는 두번째 의문에만 집중했다.
왜 입력이 다른데 같은 결과가 나올까?
심지어 원래 학습된 모델을 사용할 때는 잘 되는데…
그래서 나는 코드가 문제인가 하여 열심히 뜯어보았다.
그 과정에서 built-in function에 대해 공부하게 되었지만 여전히 코드에는 문제가 없어 보였다.
그래서 그 다음에는 아예 학습 바운더리를 벗어난 데이터에 대해 이상한 결과를 도출하는 아웃라이어라고 의심했다.
하지만 갑자기 바이올린 소리를 넣은 것도 아니고 그래도 똑같은 한국어음성인데 아웃라이어는 아닌 것 같았다.
그래서 마지막으로 오버피팅일 것이라는 결론을 도출했다.
우선은 finetuning한 데이터가 너무 적어서 overfitting될 확률이 높았고
내가 머신러닝을 공부하면서 결과가 이상하면 보통 오버피팅이었기 때문이다.
지금 생각하면 오버피팅일 리도 없는 것이, 한 번에 추론한 결과끼리 비슷해지는 오버피팅이 어디 있는가…
출력된 inference 결과는 pretraining 한 데이터와도, finetuning시 사용한 데이터와도 거리가 멀었다!
나는 그냥 답을 모르겠어서 “오버피팅인가보다~” 하고 넘긴 것 같다..
아직 공학도로서 너무나 부족한 논리고 꼭 고치고 싶은 안일함이다..
사실 아직도 잘못된 결과끼리 비슷해지는지 궁금하다.
심지어… 이를 구글링하는 과정 중에서 sampling rate를 잘 맞추라는 언급이 있었으나
“이건 프로젝트니까 이런 부분은 출제자가 알아서 맞췄겠지~”하고 안일하게 넘어갔다.
나만 틀린 것은 아니였지만 너무 부끄럽고 안일했다는 생각이 들었다.
한편으론 열심히 한 과제에서 치명적인 실수를 한 내 실력이 한탄스러웠다.
특히 한 학부생은 정확히 문제의 답을 찾고 이후 lr을 조절하여 성능을 높이기까지 했는데
나는 음성인식 엔지니어 공부를 하는 사람임에도 성능에 대한 부분을 신경을 못썼다는 점이 부끄러웠다.
글을 정리하는 지금은, 부끄러움 보다는 더 기본에 충실해져서 이제 다시 그런 사소한 실수를 하지 않고 싶다는 생각이 든다.
많은 것을 느낄 수 있는 프로젝트를 만들어준 연구실언니에게 고맙다.
마지막으로 이번에 깨달은 교훈으로 글을 마친다.
결과가 이상하다면 예민하게 원인을 분석하자