이번 주부터 '밑바닥부터 시작하는 딥러닝' 복습을 시작했다.
딥러닝 입문자분과 딥러닝 고수분, 그리고 나 이렇게 셋이서 스터디를 한다.
그런데 아주 첫부분에서 선배가 0에서의 ReLU값이 무엇인지 물어봤다.
어... 미분 불가라 미분값이 없지 않나요?
하지만 선배가 물어본 것은 이런 대답이 아니었다.
활성함수로 ReLU를 자주 사용하는데 그 경우마다 0의 값이 하나도 없을까?
그 때는 오류를 내고 그냥 넘어가는가?
당연히 아니다.
좌극한값 0 또는 우극한 값 1을 넣어줄 것이다.
물론 정확히 0인 경우가 얼마나 되겠냐만은, 무시할 수 없는 부분인 것은 확실하다.

이것이 ReLU다.
정의를 보면 굉장히 간단하다.
그럼 DeepLearning에서 흔히 쓰이는 library 두 가지, TensorFlow와 PyTorch에서 ReLU를 어떻게 정의했는지 살펴보자.
1. TensorFlow
https://www.tensorflow.org/api_docs/python/tf/nn/relu

2. PyTorch
https://pytorch.org/docs/stable/generated/torch.nn.ReLU.html

둘 다 공통적으로 아래 식을 사용하는 것을 알 수 있다.
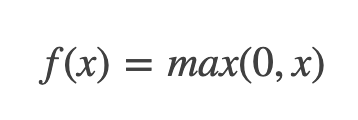
그런데 다른 사이트를 확인해보면

이렇게 정의되어 있다.
이 범위대로라면 아마도 미분도 위 범위로 이루어지고, 좌극한 값을 사용할 것이라고 추측할 수 있다.
하지만 이렇게 범위를 나누는 것은 출처마다 모두 다르고, 무엇보다 미분값에 대한 정의도 아니다.
그렇다면 과연 정말 0에서의 미분값은 0일까 1일까?
**여담
선배에게 설명하다가 soft ReLU를 생각하면서 leaky ReLU라고 잘못 말했다.
이 둘은 완전히 다른데, 이따금 헷갈린다.

이렇게 0에서의 값이 soft하게 바뀌는 것이 soft ReLU다.

이렇게 음의 입력값에서 값이 새는(leak) 함수가 Leaky ReLU다.
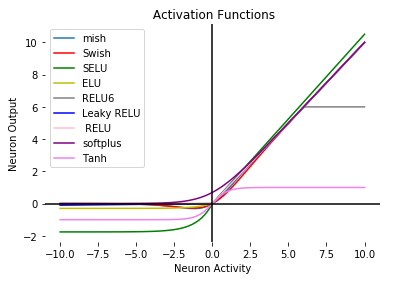
추가로, 이렇게 여러가지 ReLU에서 파생될 활성함수는 아주 많고, 또 계속 생기는 중이다.
입력 data에 따라 가장 성능이 좋은 활성함수도 달라지기 때문에 상황에 따라 잘 골라 선택해야 한다.
'전공 > 인공지능, ML, DL' 카테고리의 다른 글
| 2023 인공지능 툴 결산 / Best 12 AI Tools in 2023 (2) | 2024.02.14 |
|---|---|
| 인공지능으로 트렌드 파악하기 (0) | 2024.01.12 |
| [Deep Learning from Scratch 1] 밑바닥부터 시작하는 딥러닝 1 리뷰 (0) | 2022.06.24 |
| Batch, mini batch 배치와 미니배치 그리고 여러가지 경사하강법 (0) | 2022.01.08 |
| K-L 다이버전스 (Information theory, log, ...) (2) | 2022.01.02 |



댓글